
介绍:两台或以上数据库实例,通过二进制日志,实现数据的“同步一致”关系。
主从复制的前提:
- 至少两台以上时间一致、网络畅通的数据库实例,要有角色划分(有从库有主库),server_id要不同
- 主库开启binlog,建立专用复制用户
- 从库需要知晓主库的连接信息,并确认复制起点
- 从库需要开启专用的复制线程
主从复制的搭建过程:
1. 准备两个mysql实例,假设mysql1是主库,mysql2是从库
2. 检查两个mysql实例的server_id要不同:mysql>select @@server_id;
3. 主库需要开启binlog:mysql>select @@log_bin;
4. 主库建立复制用户:mysql>grant replication slave on *.* to rep1@'10.0.0.%' identified by '123'; 检查是否建立复制用户成功:mysql>select user,host from mysql.user;
5. 主库备份恢复到从库:主库备份 mysqldump -A --master-data=2 --single-transaction >/tmp/all.sql,从库恢复 source /tmp/all.sql
6. 从库设置主库的连接信息、复制起点,执行以下命令,mysql> change master to master_host='10.0.0.51', master_user='rep1', master_password='123', master_port=3306, master_log_file='bin.000002', master_log_pos=444, master_connect_retry=10;
7. 从库开启主从复制:mysql>start slave;
8. 验证从库的主从复制开启状态:mysql>show slave status;
9. 从库清除主从复制:mysql>stop slave; reset slave all;
主从复制原理
主从复制涉及到的资源
文件
主库:binlog文件
从库:
- relay-log文件,用来存储接收到的binlog,如db01-relay.000001
- master.info文件,用来记录连接主库的信息,已经接收binlog的位置点信息
- relay-log.info文件,用来记录从库回放到的relay-log的位置点
线程
主库:binlog_dump_thread,用来接收从库的请求,并投递binlog给从库;通过mysql>show processlist; 命令可以查看到
从库:
- IO线程:请求主库binlog日志,接收binlog日志
- SQL线程:回放relay日志
主从复制原理图
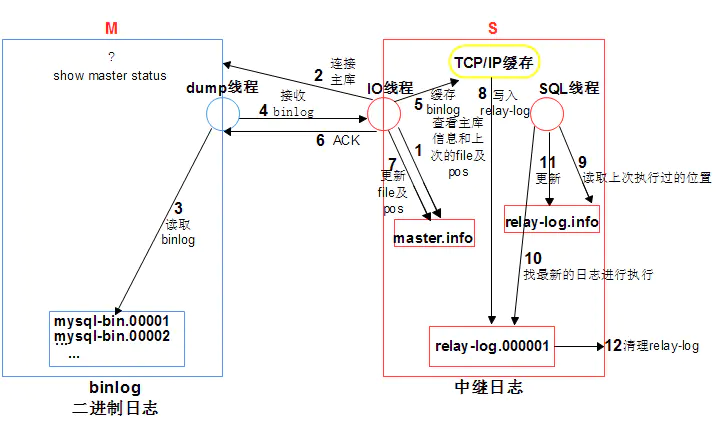
文字描述:
1.change master to 时,ip pot user password binlog position写入到master.info进行记录
2. start slave 时,从库会启动IO线程和SQL线程
3.IO_T,读取master.info信息,获取主库信息连接主库
4. 主库会生成一个准备binlog DUMP线程,来响应从库
5. IO_T根据master.info记录的binlog文件名和position号,请求主库DUMP最新日志
6. DUMP线程检查主库的binlog日志,如果有新的,TP(传送)给从从库的IO_T
7. IO_T将收到的日志存储到了TCP/IP 缓存,立即返回ACK给主库 ,主库工作完成
8.IO_T将缓存中的数据,存储到relay-log日志文件,更新master.info文件binlog 文件名和postion,IO_T工作完成
9.SQL_T读取relay-log.info文件,获取到上次执行到的relay-log的位置,作为起点,回放relay-log
10.SQL_T回放完成之后,会更新relay-log.info文件。
11. relay-log会有自动清理的功能。
细节:
1.主库一旦有新的日志生成,会发送“信号”给binlog dump ,IO线程再请求
主从监控
主库方面:
show processlist;
show slave hosts;
从库方面:
show slave status \G
主从故障分析及处理
IO线程
连接原因:
- 网络,端口,防火墙
- 复制用户账密问题,授权问题
- 主库达到连接数上限,select @@max_connections;
- 主从库版本不统一
mysql>start/stop io_thread/sql_thread; 单独开关io、sql线程的命令
请求日志原因:
- 主库二进制日志不完整,如文件损坏、不连续等
- 从库请求的起点有问题
- 主从间的server_id、server_uuid相同
- 从库的relay-log有问题
SQL线程
可能原因:
- 创建的对象已经存在,比如建库表时,库表已经存在
- 操作的对象不存在,比如表不存在无法插入
- 约束冲突,如唯一键、非空约束等
- 参数、版本不一致
以上问题,大概率出现在从库写入或者双主结构中。
处理思路:
- 以主库为准,将从库反向操作下
- 以从库为准,跳过某个操作或者跳过报错
- 第三方工具,pt工具(Percona-toolkit)
主从延时问题的原因分析及处理
介绍:主库发生了操作,从库很久才跟上来。
主从延时监控:
- show slave status \G 命令结果中的 seconds_behind_master 的值,但是这个并不一定准确,用作粗略评估
- 评估主从延时更精确的指标是,延时了多少日志量,主库和从库执行的日志的对比,主从binlog的位置点对比
如何计算延时的日志量:
- 使用位置号比较,分别查看主从的binlog文件的position位置号,如果两个位置号相差较大,可判定为延时严重(需要考虑主从的binlog文件不一样的情况,如果文件不一样,可直接判定为延时严重)。主库可通过 show master status; 命令查看,从库可查看 relay-log.info文件。
- 使用GTID号比较,分别查看主从的binlog的gtid号,因为gtid是递增的,所以如果两个gtid相差较大,可判定为延时严重
主从复制延时原因:
主库:
外部原因:
- 网络。升带宽。
- 硬件配置。升硬件。
- 主库业务繁忙。拆分业务(分布式)(组件分离、垂直水平拆分);大事务拆分(分多次执行)。
- 从库太多。减少从库,设计多级从库。
内部原因:
- binlog日志及时更新。设置参数 sync_binlog=100。sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。
- 开启GTID,可以加速binlog的传输。有了GTID,可以实现并发传输binlog。同时减少大事务,以及锁的影响,也可以提升性能。
怎么判断是主库传输不及时导致的主从延迟?
- 通过seconds_behind_master的值判断。
- 主库show master status; 从库 show slave status\G,如果主从间的位置号相差比较大,一般就是主库传输不及时导致的。
从库:
外部原因:
- 网络
- 硬件配置低
- 参数设定
内部原因:
- IO线程,写relay-log,考验IO性能。
- SQL线程,在非GTID模式下是串行回放SQL的,所以可以开启GTID,串行变为并行(MTS模式)。
要注意大事务的处理问题,和锁的等待问题!
特殊从库的应用
延时从库
延时从库:主库做了某项操作以后,从库延时一段时间再回放。
配置方法(从库执行):
mysql>stop slave;
mysql>change master to master_delay=300; # 秒为单位
mysql>start slave;
mysql>show slave status\G
SQL_Delay: 300
SQL_Remaining_Delay: NULL
过滤复制
过滤复制:只复制某些库/表,不复制某些库、表。
配置方法有两种,可以在主库设置,也可在从库设置。一般在从库设置,减少主库压力。
从库配置方式:
只能配置一种级别的哦!
库级别:
[root@db01 ~]# vim /data/3309/my.cnf
replicate_do_db=ppt
replicate_do_db=word
replicate_ignore_db=ppt2
replicate_ignore_db=word2
[root@db01 ~]# systemctl restart mysqld3309
表级别:
[root@db01 ~]# vim /data/3309/my.cnf
replicate_do_table=ppt.t1
replicate_ignore_table=ppt.t2
[root@db01 ~]# systemctl restart mysqld3309
表级别 模糊匹配:
[root@db01 ~]# vim /data/3309/my.cnf
replicate_wild_do_table=ppt.t1*
replicate_wild_ignore_table=ppt.t2*
[root@db01 ~]# systemctl restart mysqld3309
show slave status\G 查看验证下
半同步复制
解决主从数据一致性问题
半同步复制需要安装插件的哦。
原理:
1. 主库执行新的事务,commit时,更新 show master status\G ,触发一个信号给
2. binlog dump 接收到主库的 show master status\G信息,通知从库日志更新了
3. 从库IO线程请求新的二进制日志事件
4. 主库会通过dump线程传送新的日志事件,给从库IO线程
5. 从库IO线程接收到binlog日志,当日志写入到磁盘上的relaylog文件时,给主库ACK_receiver线程
6. ACK_receiver线程触发一个事件,告诉主库commit可以成功了
7. 如果ACK达到了我们预设值的超时时间,半同步复制会切换为原始的异步复制.(那就没什么卵用了......)
很明显,半同步复制挺影响性能的。
如果生产业务比较关注主从的数据一致性(金融类业务),推荐使用MGR架构或者PXC等一致性架构。
GTID复制
作用:主要保证主从复制中的高级的特性,如提高并行度的。
先不了解了呢,以后再说吧。
主从复制架构演变
原生态支持:一主一从、一主多从、多级主从、双主结构(互为主从)、延时主从 、过滤复制、MGR组复制
非原生态:高可用架构
读多写少,读写分离方案,代表产品:altas、proxysql、mycat等
读多写多,分布式方案,代表产品:mycat、sharding-jdbc等